Speaker
Overview
DJI PSDK enables developers to develop megaphone loads that meet various search, rescue and patrol scenarios, and provides standard megaphone solutions, including real-time shouting, text-to-speech (TTS), volume control and playback mode control and other functions. Developers do not need to develop additional apps separately, and can directly develop microphone integration through DJI Pilot.
Basic Concepts
TTS
TTS is the abbreviation of Text To Speech, which is "from text to speech", which is a part of human-machine dialogue, a text-to-speech technology that enables machines to speak. At present, the development of TTS technology is relatively mature, mainly including two types, one is audio synthesis through dedicated TTS hardware chips, and the other can be converted and synthesized through TTS online or offline software libraries, such as Xunfei Offline Speech Synthesis SDK.
PCM data
The raw data format of audio is Pulse Code Modulation (PCM) data. It is a digital signal produced by sampling, quantizing and encoding a continuously changing analog signal. Describing a piece of PCM data generally requires the following concepts: quantization format, sampling rate (sampleRate), and number of channels (channel).
Opus Audio Codec
Opus is a completely open, royalty-free, versatile audio codec. It is suitable for interactive voice and music transmission over the Internet, but also for storage and streaming applications.
The predecessor of Opus is the celt encoder. In today's competition for lossy audio formats, the AAC format with many different encoders has defeated the equally promising formats such as Musepack and Vorbis, but after the birth of the Opus format, the situation seems to be different. Through many comparative tests, Opus completely outperformed HE AAC, which used to have obvious advantages at low bit rates. At medium bit rates, it was already comparable to the AAC format with a bit rate that was about 30% higher than that of the enemy, while at high bit rates it was closer to the original audio.
Opus can handle a variety of audio applications, including voice over IP, video conferencing, in-game chat, and even remote live music performances. It can scale from low bit rate narrowband speech to very high quality stereo music. Supported features include:
- Bit rate from 6kb/s to 510 kb/s
- Sampling rates from 8kHz (narrowband) to 48kHz (full band)
- Frame size from 2.5ms to 60ms
- Support Constant Bit Rate (CBR) and Variable Bit Rate (VBR)
- Audio bandwidth from narrow to full band
- Support voice and music
- Support mono and stereo
- Support up to 255 channels (multi-stream frame)
- Dynamically adjustable bit rate, audio bandwidth and frame size
- Good robustness and concealment
- floating point and fixed point implementation
Sampling Rate
The audio sampling rate refers to the number of times the recording device samples the sound signal in one second. The higher the sampling frequency, the more realistic and natural the sound will be. On today's mainstream capture cards, the sampling frequency is generally divided into five levels: 11025Hz, 22050Hz, 24000Hz, 44100Hz, and 48000Hz
The frequency corresponds to the time axis, and the amplitude corresponds to the level axis. The wave is infinitely smooth, and the string can be regarded as composed of countless points. Since the storage space is relatively limited, the points of the string must be sampled in the process of digital encoding. The sampling process is to extract the frequency value of a certain point. Obviously, the more points are extracted in one second, the more abundant frequency information can be obtained. In order to restore the waveform, there must be 2 points of sampling in one vibration. The highest frequency that the human ear can perceive is 20kHz, so to meet the hearing requirements of the human ear, at least 40k samples per second are required, expressed in 40kHz, and this 40kHz is the sampling rate. Our common CD has a sampling rate of 44.1kHz.
For the megaphone load mounted on the drone, audio encoding needs to be performed from the ground-side remote controller and uploaded to the aircraft side. In order to maximize the transmission efficiency, a trade-off between sound quality and sampling rate is required.
channel
Channels refer to independent audio signals that are collected or played back at different spatial positions during recording or playback, so the number of channels is the number of sound sources during sound recording or the number of corresponding speakers during playback.
For the megaphone load mounted on the drone, due to the limitation of the drone's load and power, a single-speaker solution, that is, a single channel, is generally selected.
Speaker Introduction
DJI Pilot 2 supports displaying the standard speaker widget. Users can control whether display the icon by configuring the speaker json field of custom widget
Notice: Before using the speaker, the custom widget should be enabled first.
Voice Speaking
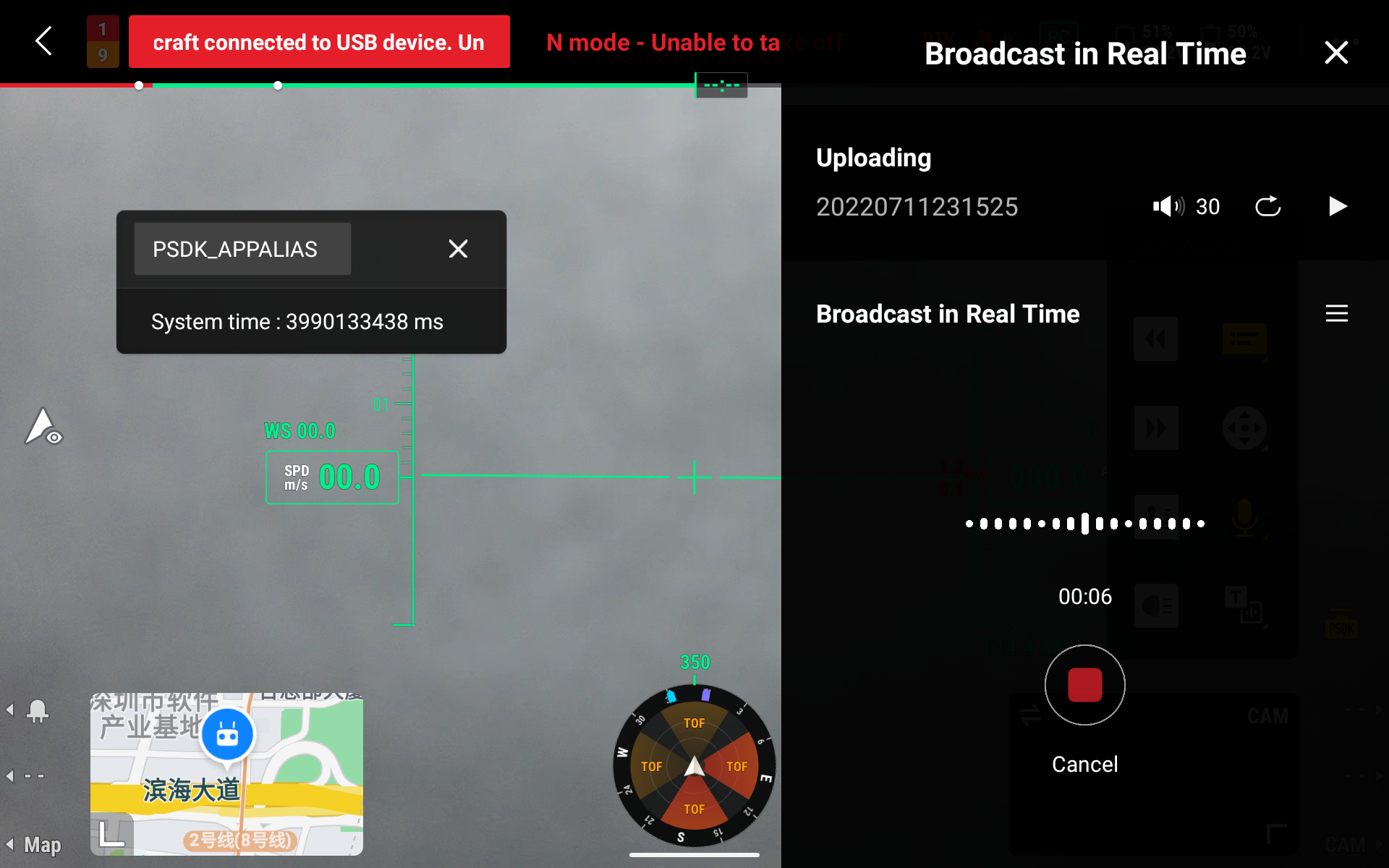
Use can record the content that needs to be spoken through "press to speak". During the recording, the Pilot has timekeeping. When the time is close to the maximum recording time, the remote controller will shake and have interactive notifications. When the recording is finished, after the user presses the "Stop" button, the "local audition" or "speak" button can be pressed to play. In addition, when the recording result is not satisfying, it can be recorded again, or saved in the recording file to manage the voice list. The audition, file information display, deletion, rename, upload and play are supported.
| Time Limitation | Voice Parameter | Code Parameter |
|---|---|---|
| Maximum 3mins | 16khz, mono,16bit | opus@16kbps Single frame data is 160 bytes. |
Hotkey Speaking
In emergency situations, Pilot Pilot supports quickly call out the recording call window through the custom button of the remote control, and you can "record-upload-play" with one key on the remote control. 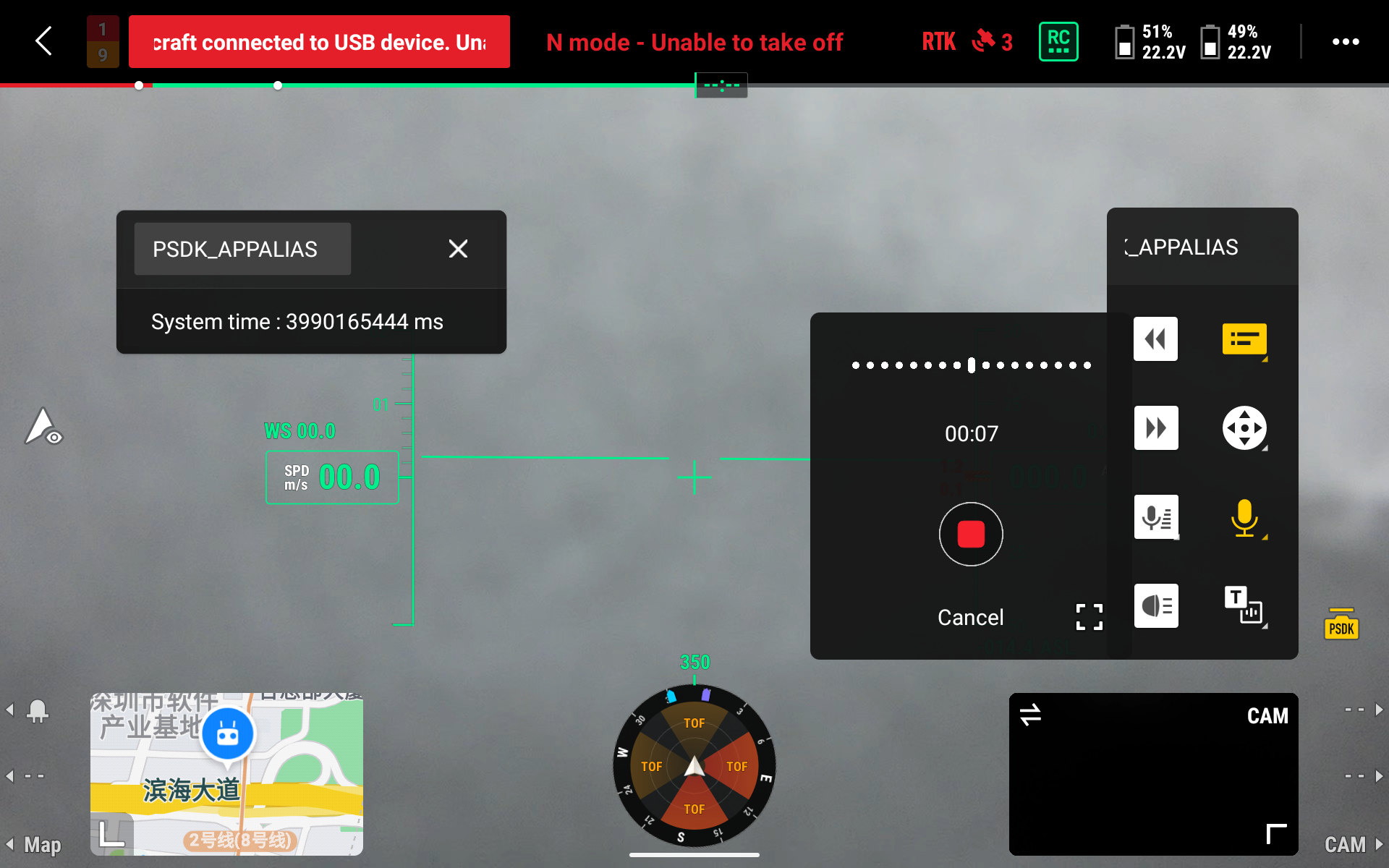
TTS Speaking
Users can directly enter the text that needs to be spoken in the text input box in the widget, DJI Pilot 2 will transfer the text to the Speak side. The speaker side will automatically realize the TTS function by itself. 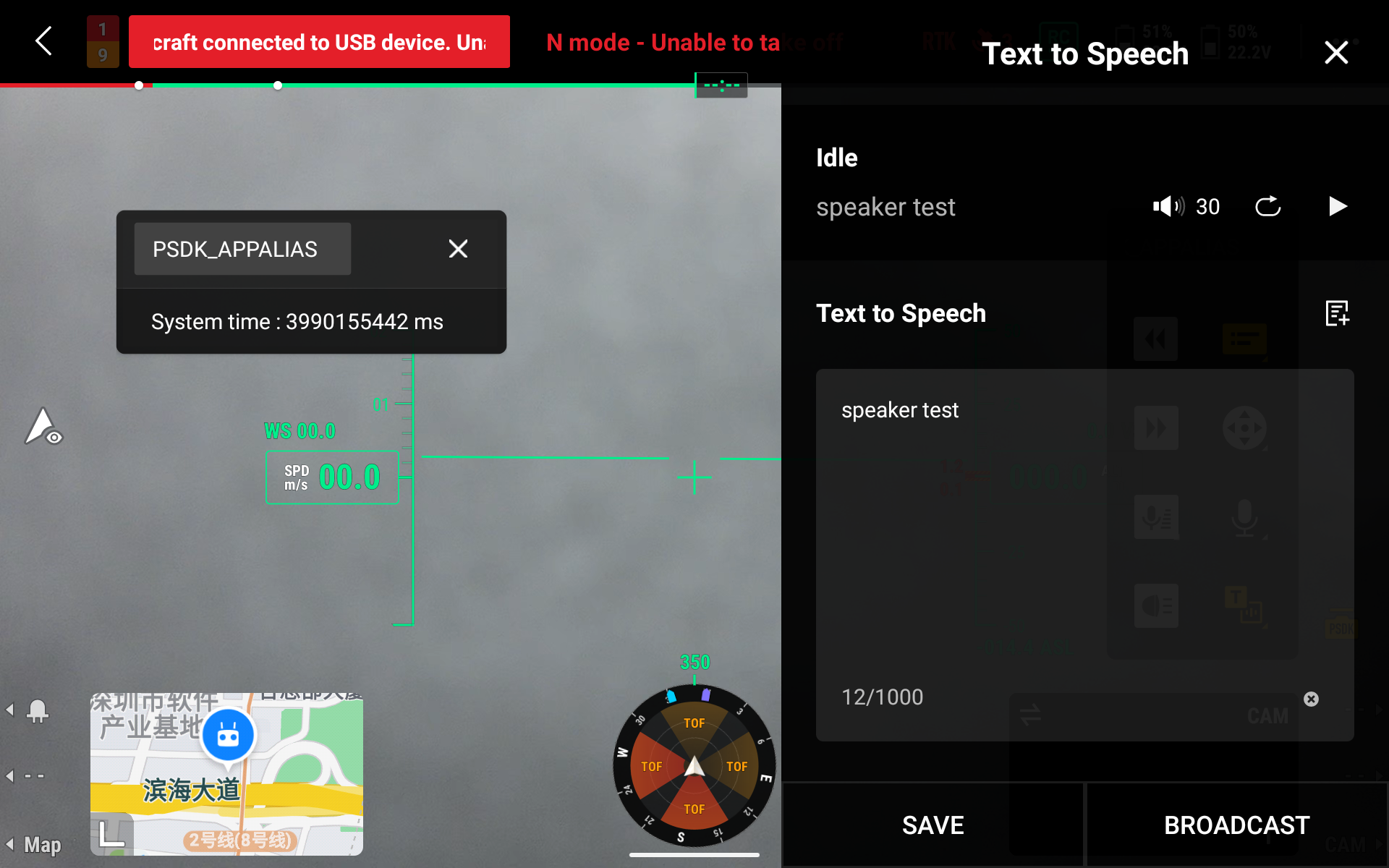
Input the voice file to speak
The speaker function supports users to input voice files from Pilot and upload them to the speaker for playing. Users will easily manage the voice file list. The audition, file information display, deletion, rename, upload and play are supported.
| Format Limitation | Size Limitation | Maximum Amount |
|---|---|---|
| MP3/WAV/AAC | 10MB | 20 |
Input the text to speak
Speaker supports the users to input text from Pilot and upload them to the speaker for playing. Users will easily manage the text list. Preview, deletion, and upload playing are supported.
Character limitation: 1000 characters(One Chinese word is one character).字符限制:
Megaphone audio parameters
Due to the load, power and uplink limitations of the drone, the microphone function limits the relevant parameters of the audio in order to meet the needs of various usage scenarios.
- Number of channels: 1
- Sampling rate: 16 kHz
- Bit width: 16 bit
Using the megaphone function
1. Initialize the control module
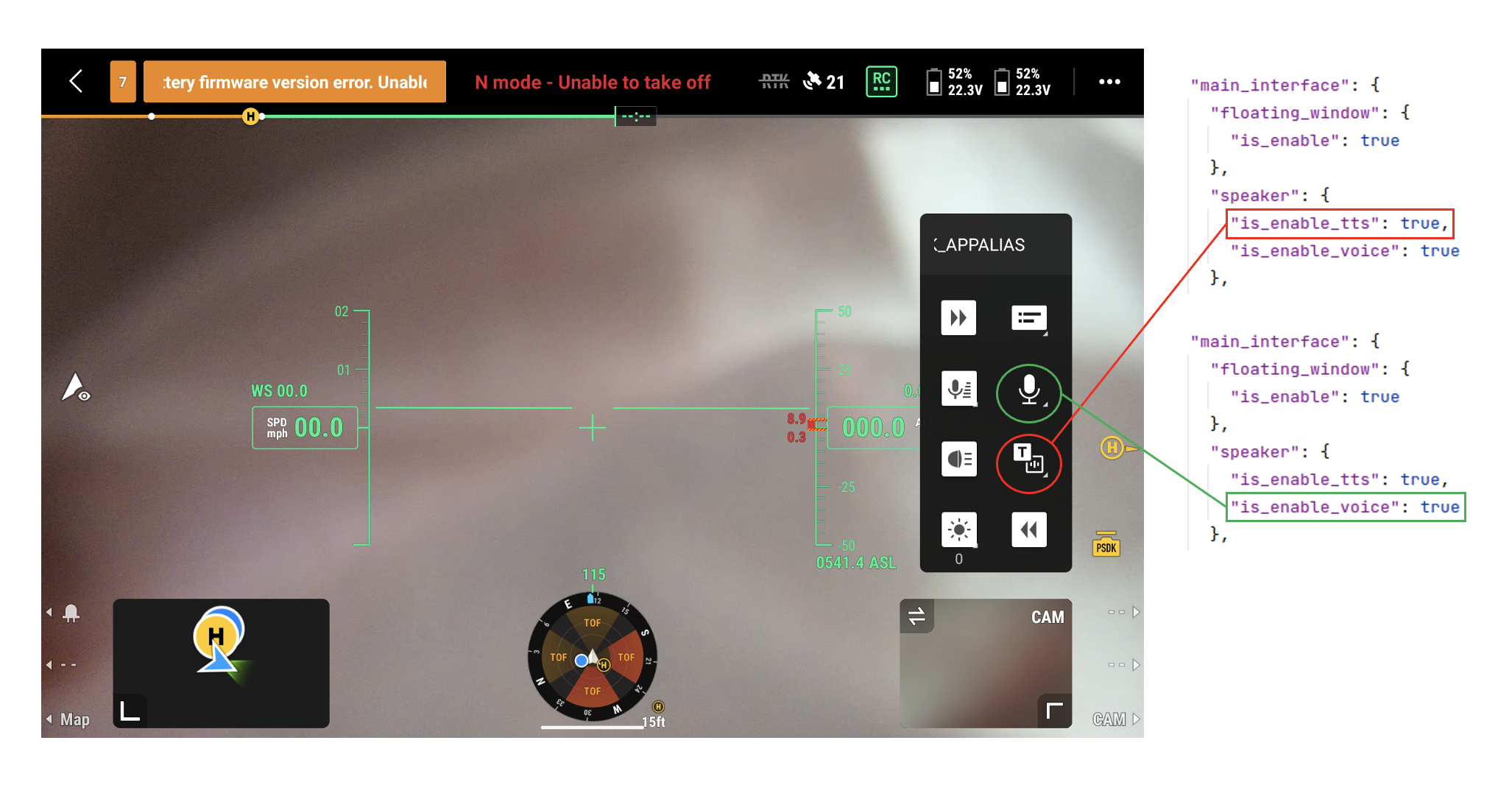
For the display of the loudspeaker controls, you can control the display of the loudspeaker TTS icon and the voice call icon on the DJI Pilot side through the json field in the speaker option.
Note: Before using the loudspeaker function, you need to enable the widget function.
"main_interface": {
"floating_window": {
"is_enable": true
},
"speaker": {
"is_enable_tts": true,
"is_enable_voice": true
},
2. Register the megaphone callback function
To implement the loudspeaker function, you need to call the DjiWidget_RegSpeakerHandler interface to register the implementation method of the specific function of the loudspeaker.
T_DjiReturnCode returnCode;
T_DjiOsalHandler *osalHandler = DjiPlatform_GetOsalHandler();
s_speakerHandler.GetSpeakerState = GetSpeakerState;
s_speakerHandler.SetWorkMode = SetWorkMode;
s_speakerHandler.StartPlay = StartPlay;
s_speakerHandler.StopPlay = StopPlay;
s_speakerHandler.SetPlayMode = SetPlayMode;
s_speakerHandler.SetVolume = SetVolume;
s_speakerHandler.ReceiveTtsData = ReceiveTtsData;
s_speakerHandler.ReceiveVoiceData = ReceiveAudioData;
returnCode = DjiWidget_RegSpeakerHandler(&s_speakerHandler);
if (returnCode != DJI_ERROR_SYSTEM_MODULE_CODE_SUCCESS) {
USER_LOG_ERROR("Register speaker handler error: 0x%08llX", returnCode);
return returnCode;
}
3. Implement megaphone audio transmission
The audio transmission of the megaphone needs to be implemented through the corresponding callback interface. When the megaphone is in TTS mode, TTS text data can be received in the ReceiveTtsData callback; when the megaphone is in the real-time shouting mode, in the ReceiveAudioData callback Opus audio encoded data can be received.
In the process of receiving data, it is necessary to start receiving, transmitting data and completing three stages:
- Start receiving: The APP will send a command to the megaphone, and the megaphone is ready to start receiving audio data.
- Transmission data: The APP will send the serial number, length and encoded data of the audio data.
- Complete reception: The APP will send the MD5 value of the audio data, and provide it to the megaphone load to verify the audio data.
The implementation is as follows:
static T_DjiReturnCode ReceiveAudioData(E_DjiWidgetTransmitDataEvent event,
uint32_t offset, uint8_t *buf, uint16_t size)
{
uint16_t writeLen;
T_DjiReturnCode returnCode;
if (event == DJI_WIDGET_TRANSMIT_DATA_EVENT_START) {
USER_LOG_INFO("Create voice file.");
audioFile = fopen(WIDGET_SPEAKER_AUDIO_OPUS_FILE_NAME, "wb");
if (audioFile == NULL) {
USER_LOG_ERROR("Create tts file error.");
}
} else if (event == DJI_WIDGET_TRANSMIT_DATA_EVENT_TRANSMIT) {
USER_LOG_INFO("Transmit voice file, offset: %d, size: %d", offset, size);
if (audioFile != NULL) {
fseek(audioFile, offset, SEEK_SET);
writeLen = fwrite(buf, 1, size, audioFile);
if (writeLen != size) {
USER_LOG_ERROR("Write tts file error %d", writeLen);
}
}
} else if (event == DJI_WIDGET_TRANSMIT_DATA_EVENT_FINISH) {
USER_LOG_INFO("Close voice file.");
if (audioFile != NULL) {
fclose(audioFile);
}
returnCode = DjiTest_CheckFileMd5Sum(WIDGET_SPEAKER_AUDIO_OPUS_FILE_NAME, buf, size);
if (returnCode != DJI_ERROR_SYSTEM_MODULE_CODE_SUCCESS) {
USER_LOG_ERROR("File md5 sum check failed");
}
DjiTest_DecodeAudioData();
}
return DJI_ERROR_SYSTEM_MODULE_CODE_SUCCESS;
}
4. Implement audio decoding
For the encoded audio data, it is necessary to decode the data into RAW data in PCM format. The following is an example code for the Linux platform. You need to create a decoder, read Opus data according to 160 bytes per frame, and store the decoded data in PCM format for playback.
Description: For detailed usage instructions of the Opus decoder, please refer to Opus API Documentation.
FILE *fin;
FILE *fout;
OpusDecoder *decoder;
opus_int16 out[WIDGET_SPEAKER_AUDIO_OPUS_MAX_FRAME_SIZE * WIDGET_SPEAKER_AUDIO_OPUS_CHANNELS];
uint8_t cbits[WIDGET_SPEAKER_AUDIO_OPUS_MAX_PACKET_SIZE];
int32_t nbBytes;
int32_t err;
/*! Attention: you can use "ffmpeg -i xxx.mp3 -ar 16000 -ac 1 out.wav" and use opus-tools to generate opus file for test */
fin = fopen(WIDGET_SPEAKER_AUDIO_OPUS_FILE_NAME, "r");
if (fin == NULL) {
fprintf(stderr, "failed to open input file: %s\n", strerror(errno));
return EXIT_FAILURE;
}
/* Create a new decoder state. */
decoder = opus_decoder_create(WIDGET_SPEAKER_AUDIO_OPUS_SAMPLE_RATE, WIDGET_SPEAKER_AUDIO_OPUS_CHANNELS, &err);
if (err < 0) {
fprintf(stderr, "failed to create decoder: %s\n", opus_strerror(err));
return EXIT_FAILURE;
}
fout = fopen(WIDGET_SPEAKER_AUDIO_PCM_FILE_NAME, "w");
if (fout == NULL) {
fprintf(stderr, "failed to open output file: %s\n", strerror(errno));
return EXIT_FAILURE;
}
USER_LOG_INFO("Decode Start...");
while (1) {
int i;
unsigned char pcm_bytes[WIDGET_SPEAKER_AUDIO_OPUS_MAX_FRAME_SIZE * WIDGET_SPEAKER_AUDIO_OPUS_CHANNELS * 2];
int frame_size;
/* Read a 16 bits/sample audio frame. */
nbBytes = fread(cbits, 1, WIDGET_SPEAKER_AUDIO_OPUS_DECODE_FRAME_SIZE, fin);
if (feof(fin))
break;
/* Decode the data. In this example, frame_size will be constant because
the encoder is using a constant frame size. However, that may not
be the case for all encoders, so the decoder must always check
the frame size returned. */
frame_size = opus_decode(decoder, cbits, nbBytes, out, WIDGET_SPEAKER_AUDIO_OPUS_MAX_FRAME_SIZE, 0);
if (frame_size < 0) {
fprintf(stderr, "decoder failed: %s\n", opus_strerror(frame_size));
return EXIT_FAILURE;
}
USER_LOG_DEBUG("decode data to file: %d\r\n", frame_size * WIDGET_SPEAKER_AUDIO_OPUS_CHANNELS);
/* Convert to little-endian ordering. */
for (i = 0; i < WIDGET_SPEAKER_AUDIO_OPUS_CHANNELS * frame_size; i++) {
pcm_bytes[2 * i] = out[i] & 0xFF;
pcm_bytes[2 * i + 1] = (out[i] >> 8) & 0xFF;
}
/* Write the decoded audio to file. */
fwrite(pcm_bytes, sizeof(short), frame_size * WIDGET_SPEAKER_AUDIO_OPUS_CHANNELS, fout);
}
/*Destroy the encoder state*/
opus_decoder_destroy(decoder);
fclose(fin);
fclose(fout);
5. Implement audio volume settings
For the control of the audio volume of the megaphone, an implementation method needs to be added in combination with the specific megaphone load. The following is an example program to set the sound card through the direct pactl set-sink-volume command to achieve the effect of audio volume control.
T_DjiReturnCode returnCode;
T_DjiOsalHandler *osalHandler = DjiPlatform_GetOsalHandler();
char cmdStr[128];
int32_t ret = 0;
float realVolume;
realVolume = 1.5f * (float) volume;
USER_LOG_INFO("Set widget speaker volume: %d", volume);
s_speakerState.volume = volume;
memset(cmdStr, 0, sizeof(cmdStr));
snprintf(cmdStr, sizeof(cmdStr), "pactl set-sink-volume %s %d%%", WIDGET_SPEAKER_USB_AUDIO_DEVICE_NAME,
(int32_t) realVolume);
returnCode = DjiUserUtil_RunSystemCmd(cmdStr);
if (returnCode < 0) {
USER_LOG_ERROR("Set widget speaker volume error: %d", ret);
}
6. Implement megaphone audio playback
For the playback of megaphone audio, an implementation method needs to be added in combination with the specific megaphone load. There are two commonly used methods:
- Digital to analog I2S output: For example, on the RTOS platform, a dedicated digital PA chip is generally used to complete audio playback through I2S.
- System audio output: If the Linux platform supports audio-related drivers by default, you only need to operate the sound card through the upper-layer software for audio playback, such as ffplay.
static T_DjiReturnCode DjiTest_PlayAudioData(void)
{
char cmdStr[128];
memset(cmdStr, 0, sizeof(cmdStr));
snprintf(cmdStr, sizeof(cmdStr), "ffplay -nodisp -autoexit -ar 16000 -ac 1 -f s16le -i %s 2>/dev/null",
WIDGET_SPEAKER_AUDIO_PCM_FILE_NAME);
return DjiUserUtil_RunSystemCmd(cmdStr);
}
7. Implement TTS audio synthesis
For the megaphone TTS audio synthesis, an implementation method needs to be added in combination with the specific megaphone load. There are two commonly used methods:
- Dedicated TTS hardware chip: This type of chip generally provides the protocol of the I2C or UART interface, and the text needs to be converted and sent according to the protocol format to complete the audio playback.
- Software synthesis library: Synthesize the input text and convert it into audio data by means of a software library. This type of library has higher requirements on system resources and has a more mature solution, such as Xunfei Offline Speech Synthesis SDK.
An open source TTS language library-Ekho is used in the megaphone Sample, which is only used as an example demonstration. In order to achieve a better TTS effect, Other methods are recommended.
memset(cmdStr, 0, sizeof(cmdStr));
/*! Attention: you can use other tts opensource function to convert txt to speech, example used ekho v7.5 */
snprintf(cmdStr, sizeof(cmdStr), " ekho %s -s 20 -p 20 -a 100", data);
return DjiUserUtil_RunSystemCmd(cmdStr);